
最近AI相关的各种应用可谓是火遍全球,尤其是以OpenAI研发的ChatGPT及其最新发布的GPT-4模型更是让我们这些贫民百姓狠狠体验了一把顶尖大语言模型的强大.至今国内外多家公司都在纷纷地推出自己的大语言模型,比如百度的文心一言,阿里的通义千问,谷歌的Claude,但是他们的训练和部署成本都极为昂贵,即便是仅仅使用层面进行API的调用也是一笔支出,那不妨本地搭建一个"ChatGPT"吧
开源地址(Github)
https://github.com/ymcui/Chinese-LLaMA-Alpaca
部署过程亦参考了博客
http://t.csdn.cn/3bLnp
环境准备
由于模型文件很大,为避免出现下载出错,最好使用网络代理以免失败.
Git
这个应该都有吧,没装的可以自己找找教程:)
Python
使用Anaconda安装
下载地址:https://www.anaconda.com/products/distribution#windows
下载完成后打开安装包依照指引进行安装即可,为避免手动设置环境变量的麻烦,可以在安装选项时勾选上"Add Anaconda3 to the system PATH environment variable"这一项即可.
安装完成后打开cmd,输入以下内容测试是否安装完成
conda --version
如果发现找不到相关命令,也可以cd到./Anaconda./condabin目录下使用也是可以的,只是会有些麻烦.
完成后我们创建Python虚拟环境
conda create --name cla python=3.9 -y
运行上述命令,Anaconda就会为我们创建一个Python3.9的虚拟环境了,
注意--name后的名字是可以自定义的,要激活该环境,使用
conda activate cla
Cmake与MinGW
如果你不使用llama.cpp进行模型推理与部署,可以跳过这一步.
编译器,在之后用于模型量化,如果你的电脑内存很大,你可以跳过这一步,我测试下来7B模型进行4-bit量化后内存占用仅3G左右,若不进行量化直接运行我测不出来...(16G内存直接爆了).
不过量化以后的模型确实理论上会比非量化版本差就是了,这里先来装MinGW.
建议使用包管理器安装,若想要使用安装包安装见官网https://www.mingw-w64.org/downloads/
安装Scroop,这是一个Windows系统下的包管理工具,类似于Debian的apt这种
调出PowerShell执行以下命令:
iex "& {$(irm get.scoop.sh)} -RunAsAdmin"
之后按顺序运行继续安装必要运行库以及MinGW
scoop bucket add extras
scoop bucket add main
scoop install mingw
等待完成后我们来安装Cmake,先前往官网下载安装包https://cmake.org/download/
Windows x64 Installer一栏的下载链接就是我们的目标,同样根据引导一步步完成即可,也不要忘了在安装设置时勾选"Add Cmake to the system PATH for all users"这一项.
合并模型
原版LLaMA 7B模型可以在这两个地方下载到:
- https://huggingface.co/nyanko7/LLaMA-7B/tree/main
https://ipfs.io/ipfs/Qmb9y5GCkTG7ZzbBWMu2BXwMkzyCKcUjtEKPpgdZ7GEFKm/
我是在Hugging Face上下载的,不过会少一个tokenizer_checklist.chk的文件,去IPFS上下一个就行了.当然你也可以直接从IPFS上把7B tokenizer_checklist.chk tokenizer.model 这几个都下下来就好了.
中文Alpaca 7B模型可以在这里下载到:
- https://pan.baidu.com/s/1xV1UXjh1EPrPtXg6WyG7XQ?pwd=923e
- https://drive.google.com/file/d/1JvFhBpekYiueWiUL3AF1TtaWDb3clY5D/view?usp=sharing
为了方便管理,强烈建议将两个模型分两个文件夹存放并命名好以免出问题
两个文件的目录结构如下
chinese-alpaca-lora-7b/(主文件夹)
- adapter_config.json
- adapter_model.bin
- special_tokens_map.json
- tokenizer.model
- tokenizer_config.json
original-llama-7b/(主文件夹)
- 7B/(子文件夹)
- checklist.chk
- consolidated.00.pth
- params.json
- tokenizer_checklist.chk
- tokenizer.model
回到我们之前建立的Python虚拟环境并激活,现在安装必要依赖
pip install git+https://github.com/huggingface/transformers
pip install sentencepiece==0.1.97
pip install peft==0.2.0
接下来我们先准备好几个脚本文件
- https://github.com/huggingface/transformers/blob/main/src/transformers/models/llama/convert_llama_weights_to_hf.py
- https://github.com/ymcui/Chinese-LLaMA-Alpaca/blob/main/scripts/merge_llama_with_chinese_lora.py
将这两个脚本放进你先前下载好的两个模型的所在路径
在Python虚拟环境内执行命令,将原版模型转换为HF格式
python convert_llama_weights_to_hf.py --input_dir original-llama-7b --model_size 7B --output_dir original-llama-7b-hf
如果你的模型路径和我的不一致,将--input_dir后的文件夹名改成你自己设定的即可
接下来合并两个模型:
python merge_llama_with_chinese_lora.py --base_model original-llama-7b-hf --lora_model chinese-alpaca-lora-7b --output_dir output-model
同理,如果你的文件夹名与我不同自行修改即可.
部署
我们利用llama.cpp进行模型量化,其它量化方式教程见此https://github.com/ymcui/Chinese-LLaMA-Alpaca/wiki/%E6%A8%A1%E5%9E%8B%E6%8E%A8%E7%90%86%E4%B8%8E%E9%83%A8%E7%BD%B2
先借助Git下载llama.cpp:
git clone https://github.com/ggerganov/llama.cpp
cd进入llama.cpp目录并执行以下命令:
cmake . -G "MinGW Makefiles"
make
新建一个文件夹用于放模型文件,结构如下:
my-models/
- 7B/
- consolidated.00.pth
- params.json
- tokenizer.model
在llama.cpp目录下可以找到所需的脚本文件convert-pth-to-ggml.py,在Python虚拟环境中cd到llama.cpp目录后执行以下命令:
python convert-pth-to-ggml.py my-models/7B/ 1
现在对模型进行4-bit量化 :
.\bin\quantize.exe ./my-models/7B/ggml-model-f16.bin ./my-models/7B/ggml-model-q4_0.bin 2
等待运行完成,不出问题的话现在就可以开始运行了:
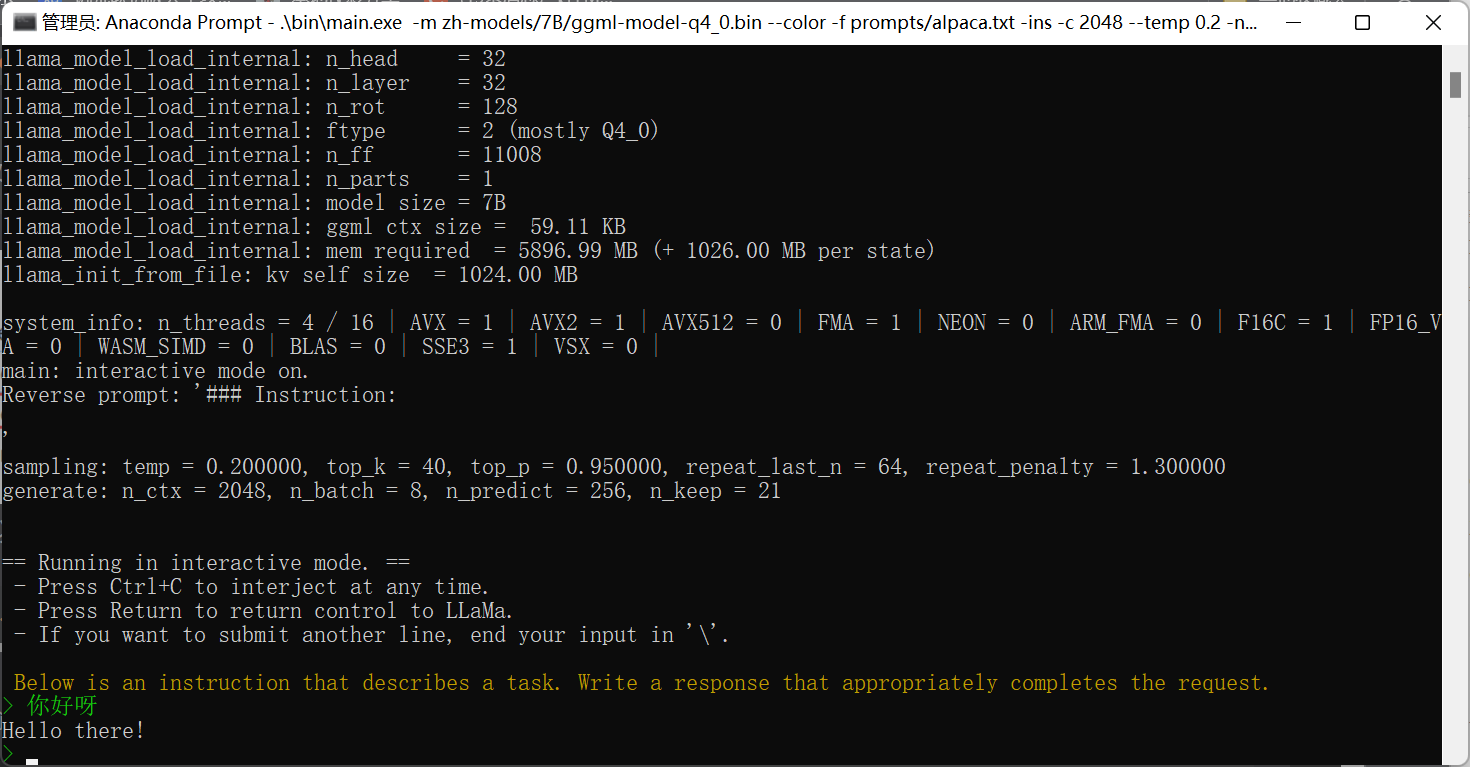
.\llama.cpp\bin\main.exe -m my-models/7B/ggml-model-q4_0.bin --color -f prompts/alpaca.txt -ins -c 2048 --temp 0.2 -n 256 --repeat_penalty 1.3
运行效果如下:
就这样吧,有空可能会补一个用text-generation-webui部署的记录?